

Any good Solutions or Data Architect should have various issues on their table at any given point in time. That’s normal. What’s abnormal is that the same problem finds its way back to that table. This is the one repeatable pattern you want to get rid of. Data Automation is about firstly finding these patterns and secondly executing on it.
Solving the solution in conceptually the right place should always be the status quo of the architect. Although this is always desired, time pressures will make us do silly things. However, when your solutions are built on repeatable patterns it somewhat forces your hand.
It is very uncomfortable to fix point solutions if they were generated by an automated process. You will make a couple of enemies by creating these siloed solutions.
By using repeatable patterns, you will be forced to zoom out and look at the problem holistically. For example, you will be forced to look at the logical data model and identify potential short comings, rather than simply adjusting some SQL code that loads data into your target object. It will highlight that your pattern isn’t perfect and thus forcing you to making it more robust.
You can always code yourself out of a sticky situation, however it is not sustainable to have bespoke coding patterns all over your ecosystem.
I am not a big proponent of no-code platforms. I am perfectly fine with high-code platforms, as long as I don’t need to write the code myself or if I do, only once. But I would be severely limited if I am not allowed to look at the code and tweak the pattern if needed.
On the topic of data automation, it would be hypocritical of me not to share this image every time I talk about it. This remains true and one should be reminded of it.

image credit: xkcd.com
Just because something is painful, doesn’t mean it isn’t the right thing to do. Setting up those initial templates and patterns are hard, but it will trump manual at some point.
Here are some of my obvious repeatable patterns that should be considered for data automation.
Loading
Regardless of your loading pattern, whether it is batch loads, a CDC approach or message driven streaming. The way you ingest data onto your desired platform or storage should be transform-light and repeatable. It should be a couple of clicks to setup the process for loading.
I am a proponent of ELT — getting your data loaded as is and transforming in target. This allows for easier modularisation of loading and then the target platform can do the hard work of optimising query plans for on target transformations.
Data transformation
The T in ETL/ELT does not have to be purely bespoke.
Modularising different functions is a good principle in many professions especially software development. Modularise the functions that is repeated often. Some examples of this is data cleansing patterns and hard business rules such as data type casting.
Conceptually (there is that word again) do the same things in the same place. Don’t cleanse and transform in 1 step. In this way you can modularise the repetitive tasks and strip them from the non-repetitive.
The T is also style dependent. For example a Data Vault modelling style is highly geared towards automation and is thus a no brainer to have a heavy focus on repeatable patterns, but even 3NF and Kimball modelling styles are highly repetitive in nature.
Choose a modelling style and stick to it. This can of course be a combination of design patterns but decide on a standard and prevent individual point variations. Sticking to the patterns that you set out for yourself, this will also force your hand in doing the right thing in the right place. By not choosing a specific modelling technique you are also making a choice — leaving the decisions in the hands of each engineer. This will result in spaghetti un-repeatable code. By all means introduce new patterns if the need arises, but introduce it as a pattern rather than giving free reign to data engineers.
Data Quality
Modularize and repeat quality checks in your data acquisition process, but make sure it lands up in the right hands.
Failed quality checks need to flow back to people who will be disincentivized for bad data. Whether that is your product owners or assigned data stewards, they need to be pro-active to get rid of data quality issues.
A simple process flow could look like this, where the “bad data” is hidden. Data can be hidden by tagging the datasets if they have failed quality checks. They can then be excluded in loading processes or hidden via views or row/column level security.
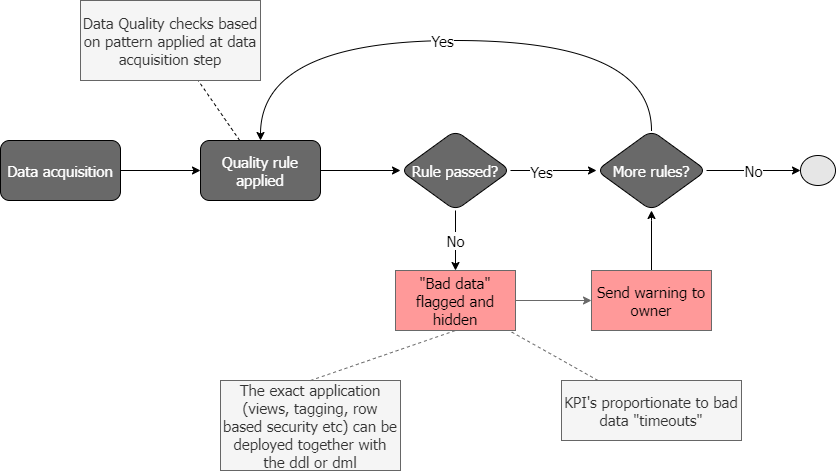
However you decide to tag, hide or exclude the failed data can be shipped as DDL statements built in to your automation process.
Distribution strategy
The distribution of data on MPP platforms are a crucial part in the life cycle and sustainability of your data platforms.
Depending on your modelling patterns this can either be highly automated or slightly automated, but there shouldn’t be no automation opportunities.
Regardless of your platform, how you should be storing data is based on several factors, like query patterns, amount of data, and whether the objects should be optimised for reading or writing. Query patterns are highly dependent on the style of data modelling you are using. A lot of these factors are known at design time and thus the distribution can be allocated at initial creation of DDL. Some require refinement over time, as your data sizes and query patterns change. This can still be automated as it continuously does health checks on your data.
Because of the repetitive and standardized nature of Data Vault as a modelling style, there is good opportunity to apply proper distribution standards with no intervention. At design time, this can be overwritten should it require changes.
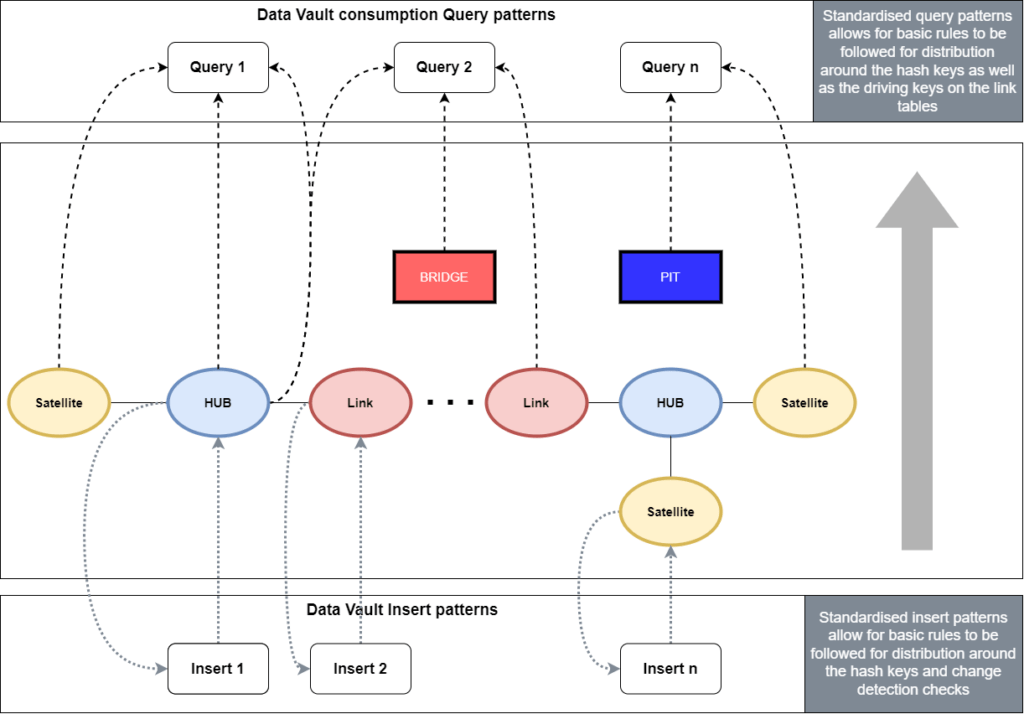
Typically, different platforms (like Synapse, Redshift and Snowflake and Delta Lake to name a few) have good documentation available on what strategies to follow regarding partitioning, distribution and clustering. They also usually have documentation to tell you how to do health checks whether your data has become skew. You can then take the learnings of this larger community and bake it into an repeatable pattern to run periodically, allowing your data to “self-heal”.
Data Security
Data security takes up a healthy amount of airtime whenever I talk to clients. It has always been important but it is becoming more nuanced. Most companies are moving to the cloud and “as a service” solutions. This, together with complexities around personal information makes it a complicated task to wrap your head around. Not only does each country have it’s own legislation, each company has its own interpretation of that legislation.
Disclaimer — automation won’t fix those nuances.
Automation does allow you to iterate and test your security policies much faster. Give the compliance team something to work with. Only lawyers can work with rules on paper, the rest of us need to see it in action.
You shouldn’t need to manually apply security policies on a user or role bases. Define policies upfront and ideally you want these to be deployable (not deplorable) at design time.
Depending on your data modelling style you could easily deploy sensitive data to different normalised tables in secure schemas (like with Data Vault), or you could keep it together but apply column or row level policies on the table with the DDL generation. Whether you mask the data, encrypt it or simply secure it from the user, most target platforms cater for some or all of these features. The design stays homogeneous, the deployment you tailor based on which target platform you are deploying to.
Testing
Much has been written about this, and I would recommend you read about testing in data ops¹ amongst others.
This is a broad topic and I will simply emphasise one aspect that I see is neglected: Curated input, curated output. To create curated datasets that can be tested against is where pain and the glory lies.
Meeting invite declines
Ok, this is a bonus one, but people are all Zoomed out. Well architected solutions goes hand in hand with well executed plans. Both need some uninterrupted focused effort from time to time.
In conclusion, when looking holistically at Data Automation there are probably many more areas functions one can automate, but I find these six play a pivotal role in the sustainability of your architecture. Continuously improving the patterns for these will force you to build well architected solutions and stop the cycle of having to fix the same issues.
Simply keep asking yourself where do repeatable patterns exists or where can they be improved – improve the pattern, rinse and repeat.
ABOUT THE AUTHORS

Corné Potgieter
Data Architect





